我让 AI 当裁判,结果它比人工专家更接近标尺
ToB AI 搜索评测真正难的,不是让 AI 给答案打分,而是把客户标准变成一套可执行、可校准、可复用、可证明可靠的评测协议。
先看一个有点反常识的结果。
在一组真实业务标注考试题上,我把评分 Agent 和人工专家评分放到同一套专家审核标尺下比较。
结果是:
| 对象 | 与专家审核标尺的一致性分数 |
|---|---|
| 评分 Agent | 80.1 |
| 人工专家评分 | 52.8 |
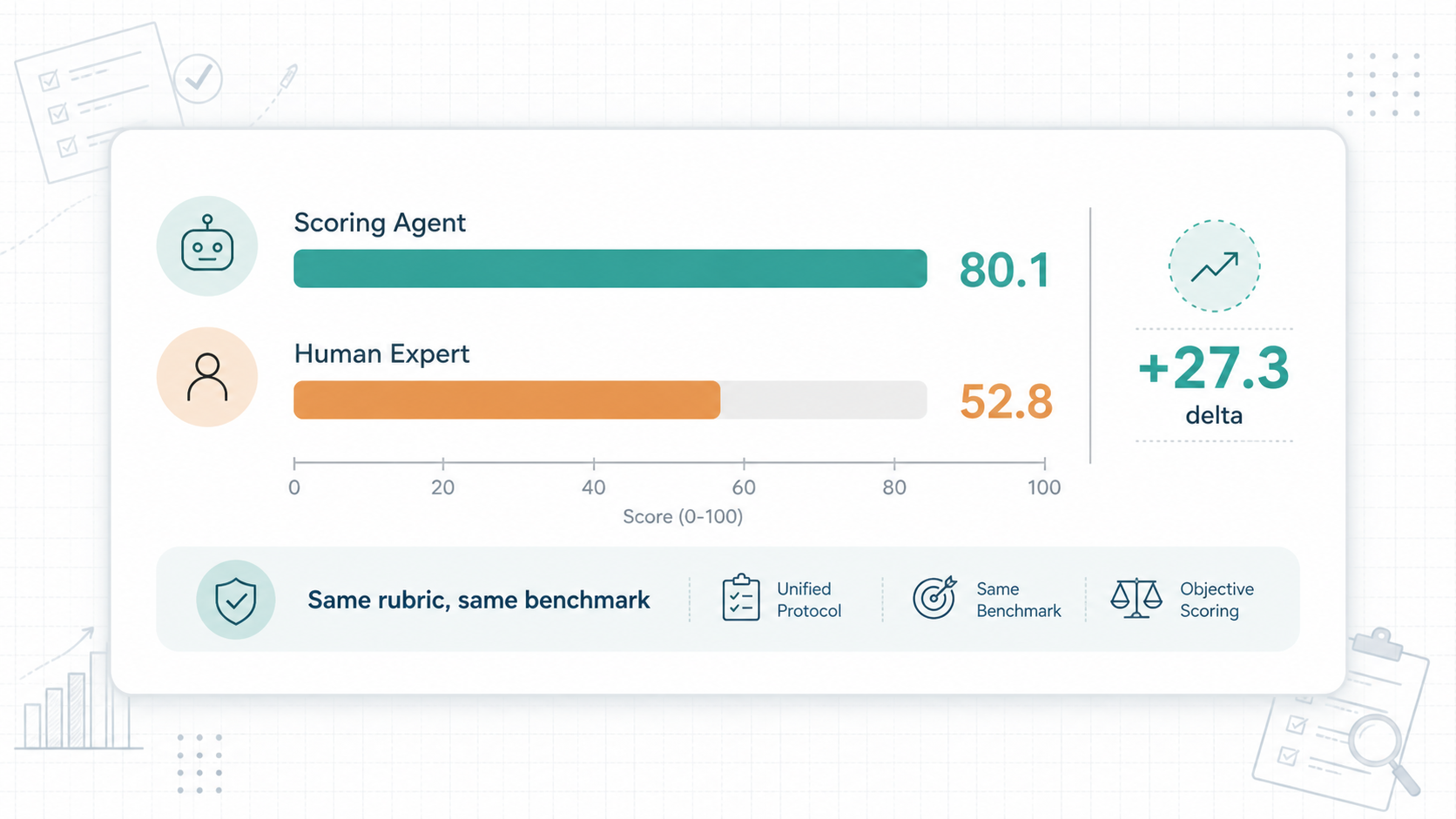
差了 27.3 分。
如果你第一反应是“是不是算错了”,很正常。
我第一次看到这个结果时,也是这个反应。
一个自动评分 Agent,为什么会比人工专家评分更接近专家审核后的标尺?
但它真正说明的事情,并不是“机器比人更懂业务”。更准确地说,它说明了另一件事:
当评测标准被结构化、流程化、工具化以后,Agent 在稳定执行同一套评分协议这件事上,可以比人工评分更接近专家审核后的标尺。
这也是我后来对 AI 搜索评测的核心判断:
评测系统的关键,不是找一个更强的大模型当裁判,而是把“裁判规则”变成一套能被执行、校准和迭代的工程协议。
我最后做出来的不是一个自动打分 Prompt,而是一套面向 ToB AI 搜索的可靠评测协议执行系统:客户标准可以文档化,文档可以变成 Agent,Agent 可以通过考试被校准,并持续反哺业务迭代。
这篇文章复盘的就是这套系统是怎么做出来的。
一、先看一个 case:人会被“像对的答案”骗过去
如果只看 80.1 vs 52.8,很容易把讨论带偏,好像重点是“机器赢了人”。
真正有意思的问题是:人为什么会漏掉这些 badcase,而 Agent 为什么能抓住?
先看一个脱敏后的真实类型案例。
有个问题大概是这样:用户问某个城市周边的一处历史景点,想知道它是不是某个著名典故的真实发生地,并希望 AI 搜索给出简短解释。
模型回答得很完整:
它先给出肯定结论,说“是,这里就是那个典故的发生地”;接着补了一段历史背景;最后还列了几条搜索结果,里面确实有网页也这么写。普通读者第一眼看,很容易觉得这个答案没问题。
但这个答案实际上是错的。
进一步查证后会发现,问题出在事实链条上:
- 回答引用的几个页面并不是权威来源,大多是旅游攻略、转载文章或二次整理内容;
- 多个页面其实互相转述同一个说法,并没有给出原始史料或官方解释;
- 当继续查当地文旅资料、景区官方说明和更严肃的历史资料时,会发现这个典故的真实发生地另有争议,不能直接肯定为该景点;
- 模型把“网上很多页面都这么说”误当成“这个事实成立”,最后给出了过度确定的结论。
这类问题最麻烦的地方在于,它不是明显胡说。它有结论、有解释、有来源,看起来像一个合格的 AI 搜索答案。
人为什么容易误判?
因为人在有限时间里评估一个搜索答案时,很容易被表达质量、结构完整性和来源数量影响。回答越流畅、越自信、越像一份完整答案,越容易掩盖事实错误。
Agent 怎么做?
不是让 LLM 直接猜这个回答有没有幻觉,而是让事实核查 Agent 抽取关键事实点:
待核查事实:
这个景点是否可以被确定为该历史典故的真实发生地。然后它会调用搜索和页面读取工具,分别查看:
- 搜索结果摘要里有哪些说法;
- 这些页面的来源类型是什么;
- 是否存在官方、权威或原始出处;
- 不同来源之间是否只是互相转述;
- 是否有更强证据反驳模型回答里的肯定结论。
最后,Agent 不会因为“有几个网页这么写”就给高分,而是会把这个回答判成事实风险 case:回答过度确定,来源质量不足,关键结论缺少可靠证据支撑。
这类 case 说明了机评超过人评的一个关键原因:
配备工具的专职事实核查 Agent,不是在评“答案像不像好答案”,而是在稳定执行一套查证协议。
这不是取代人的判断,而是把查证流程稳定化。
二、问题不是有没有 Judge,而是裁判自己也会偷懒
LLM as Judge 的出现,本质上是因为传统评测方法跟不上大模型应用。
BLEU、ROUGE 这类指标主要看词面重叠,对机器翻译、摘要这类有参考答案的任务很有价值;但到了开放式问答、复杂搜索、长文本生成场景,答案可以有很多正确写法,词面重叠就不再等价于质量。
人工评估更接近真实体验,但也有明显瓶颈:慢、贵、不可扩展,而且不同标注者之间的一致性经常不稳定。AI 搜索还会涉及本地生活、医疗、时效性、产品操作、教育考试等细分知识,标注者不可能对每个领域都熟。
所以业界很自然地走向了 LLM as Judge:让一个更强的大模型充当裁判,评价另一个模型的回答。
这个方向是对的。
但如果只是“找一个强模型,让它打分”,很快会遇到三个生产级问题。
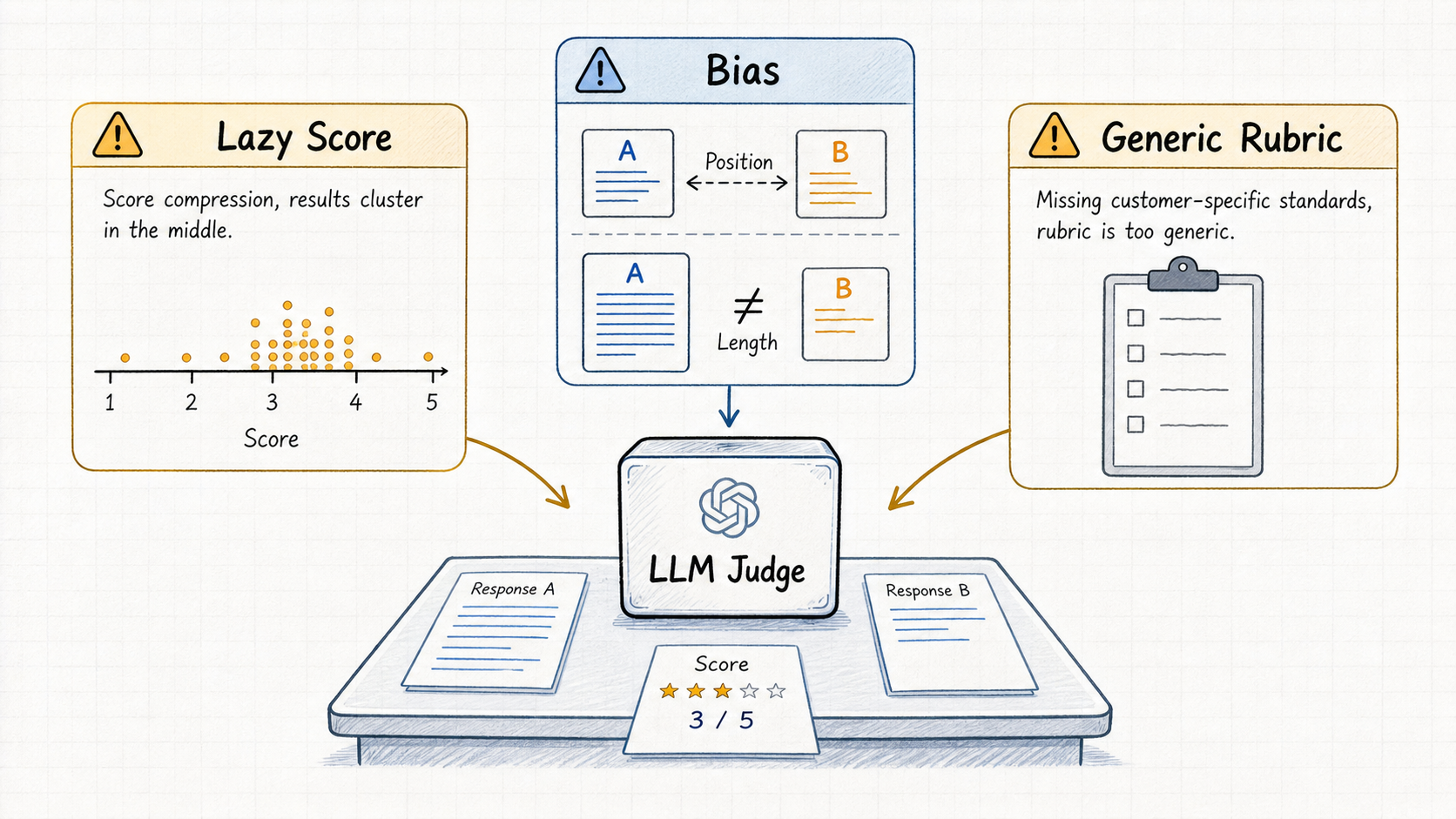
第一,Lazy Score。
很多 LLM Judge 在 1-5 或 1-10 的分值区间里,倾向于给中间偏上的安全分。大家都是 3 分、4 分,或者 7 分、8 分。平均分看起来稳定,但真正需要被拉出来的 badcase 被淹没了。
这对 AI 搜索尤其危险,因为搜索回答最怕的不是语言不流畅,而是看起来很完整,实际上事实错了。
第二,裁判偏差。
LLM Judge 会受到位置、长度、风格等因素影响。更长、更完整、更自信的回答,可能因为“看起来更好”而拿到更高分;简洁但准确的回答,反而可能被低估。
但 AI 搜索的质量不只是语言质量,还包括事实是否准确、来源是否可靠、是否理解用户意图、是否符合场景理想态、是否触及安全或行业风险边界。
第三,通用 Judge 不理解客户标准。
这是 ToB 场景最关键的问题。
不同客户对“好答案”的定义并不一样。有的客户关注端侧助手体验,有的客户关注搜索答案的权威来源,有的行业场景关注风险边界,有的时效性场景会把“新不新、准不准、有没有来源”放到最前面。
一个通用 Judge 可能觉得某个回答“内容完整、表达清楚”,但客户实际想要的是“少废话、直接回答、优先给可执行路径”。一个回答可能在通用问答里得高分,但在客户验收标准里并不合格。
所以真正的问题不是“有没有 Judge”,而是:
Judge 是否理解这个客户的评分标准?是否能稳定执行这套标准?是否能在标准变化时快速更新?
这也是我后来没有把系统设计成“固定 Prompt + 固定分数解析”的原因。我们需要的不是一个写死的评分器,而是一个可以承载客户评测协议的执行系统。
三、可靠不是一次跑高分,而是标准变了还能重新对齐
做 ToB AI 搜索评测时,我越来越觉得,“可靠”不是一个单点概念。
它至少有两层。
第一层是静态可靠。
也就是在某一版客户标准下,评分 Agent 能不能和专家审核后的标尺对齐。这里不能靠感觉,不能因为 Agent 能输出 JSON、能写 reasoning,就说它可用。它必须像人工标注员一样参加考试,在同一批题上和专家审核标尺比较。
80.1 vs 52.8 证明的是这一层:在一组真实业务标注考试题上,评分 Agent 对标尺的执行一致性更高。
第二层是动态可靠。
ToB 评测里,客户标准不是静止的。项目阶段会变,验收口径会变,badcase 会不断出现,业务同学对“好答案”的理解也会随着产品迭代变得更细。
如果一个系统只能在某一版 Prompt 下表现不错,但标准一变就要重新开发、重新调参、重新解释,那它仍然不可靠。
所以我后来对可靠性的理解变成了:
ToB 评测里的可靠性,不是标准永远不变,而是当标准变化时,系统能在足够短的周期内重新对齐客户标尺。
文档即 Agent 解决的是动态可靠:标准怎么快速进入系统。
标注考试解决的是静态可靠:进入系统以后,怎么证明 Agent 真的对齐了标准。
四、不要写死 Prompt,把客户标准变成可执行文档
传统评测系统通常是这样的:有一套固定 Prompt,有一套固定打分维度,改客户标准就要改代码、改配置、走发布流程。
这在 ToB 场景下很难接受。
因为客户标准会变,行业标准会变,验收逻辑会变。如果每一次变化都要改代码,评测就会变成 AI 搜索交付里最慢、最不可复用的一环。
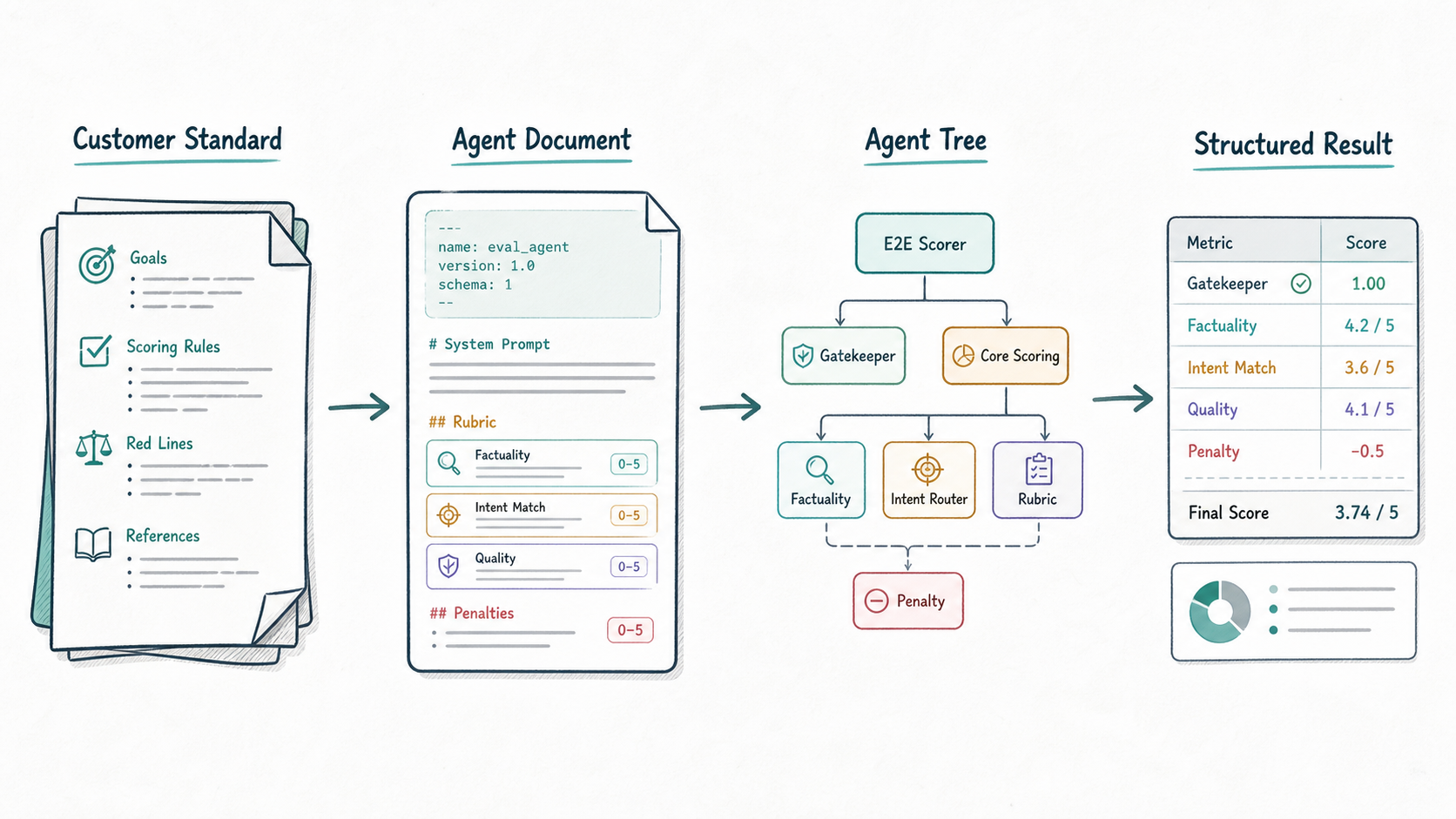
我的做法是把评分逻辑文档化。每一个评分 Agent 都可以由一份 Markdown 文档定义。文档里包括三类信息:
- 元信息:这个 Agent 的名称、职责、可调用工具、子 Agent、输出字段;
- 评分流程:先做什么,再做什么,什么时候一票否决,什么时候进入细分评分;
- 业务规则:不同意图、不同场景、不同问题类型下的 rubric 和扣分规则。
一个极简形态大概是这样:
---
name: factuality_scorer
description: 对模型回复进行事实核查
tools:
- list_search_results
- fetch_page
outputs:
- factuality_score
- factuality_reason
---
你是事实核查评分 Agent。
请基于用户 query、模型 response 和可用搜索结果,判断回答是否存在事实错误。
评分范围为 0-4 分:
- 4 分:核心事实完全正确,且有可靠来源支撑
- 3 分:整体正确,但存在轻微信息缺失
- 2 分:部分事实不准确,影响用户理解
- 1 分:核心事实存在明显错误
- 0 分:回答严重错误或完全无依据这看起来只是一个文档格式,但背后的设计哲学很关键:
评测逻辑不应该被硬编码在工程代码里,而应该沉淀在可读、可审计、可迭代的业务文档里。
客户负责定义“什么是好”,我们负责把“什么是好”进一步构建成系统可以执行、可以考试、可以复盘的评测文档。
文档化之后,系统运行时会把这些文档解析成 Agent 配置,再动态构建出一棵 Agent Tree。这样客户标准的变化,优先体现为文档变化;平台能力的复用,体现在统一的 Agent 运行时、工具系统、结果提交和可观测链路里。
五、单 Prompt 扛不住复杂标准,让评测逻辑长成一棵树
Markdown 驱动解决的是“客户标准怎么快速进入系统”的问题。
但要让机评真正稳定,架构上还需要把评测任务拆细。
如果只靠一个 Prompt 打分,很容易重新掉回通用 Judge 的问题:分值压缩、表层判断、事实核查不足、客户标准执行不稳定。
所以我没有把评测做成一个单点 Judge,而是把它拆成一棵由文档驱动的 Agent Tree。
这里最重要的一点是:
Agent Tree 的价值,不在于固定分成几层,而在于让复杂评测逻辑可以像业务流程一样被拆解、组合、校准和替换。
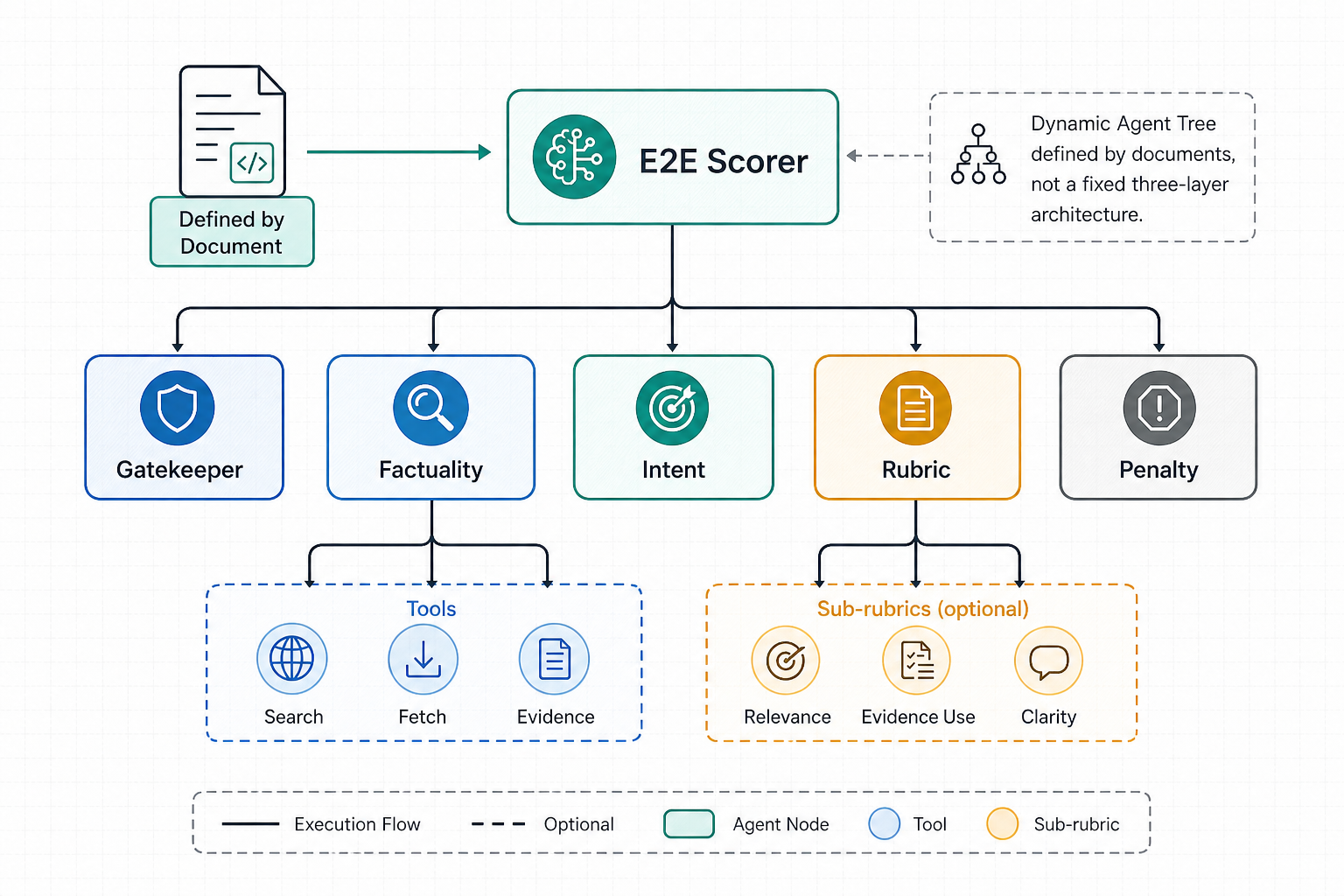
一棵典型 AI 搜索评分树,可能会包含这些节点:
Gatekeeper 做红线审查。
严重安全风险、严重拒答、完全答非所问、任务失败、明显不符合业务边界的问题,不应该和普通质量问题一起打平均分。这些问题应该先被拦截。
if gatekeeper == fail:
final_score = 0
else:
continue quality scoringFactuality 做事实核查。
AI 搜索产品的生命线是事实准确。一个回答语言很好、结构很好,但关键事实错了,对搜索产品来说仍然是坏答案。事实核查 Agent 会把回答里的关键事实点拆出来,结合搜索结果或外部页面做核验。
Intent Router 和 Rubric 做体验质量评估。
同样是搜索问答,“好”的标准不一样。找信息类 query,核心是问 A 答 A、事实准确、结构清楚;找解法类 query,核心是步骤可执行、有情形区分、有闭环验证;找观点类 query,则要看观点是否有理有据、是否平衡、是否符合场景。
Penalty 做规则扣分。
重复、格式问题、严重冗余、引用缺失、答非所问等硬伤,可以部分规则化,没必要全部交给 Judge 主观判断。
最终分数不是直接让模型拍脑袋,而是按协议汇总:
Final Score =
Gatekeeper
× (Factuality Score × W_fact + Rubric Score × W_rubric)
- Penalty这个公式背后的含义很明确:
- Gatekeeper 是一票否决,触红线直接清零;
- Factuality 权重更高,优先解决搜索回答里的幻觉和事实错误;
- Rubric 解决“好不好”的问题,按客户标准和用户意图评分;
- Penalty 处理重复、废话、格式、冗余等硬伤。
这棵树只是一个场景下长出来的实例。系统真正提供的是动态构建能力:只要评测逻辑能被拆成节点、输入、工具、输出和汇总规则,就可以通过文档组织成对应的 Agent Tree。
六、标准一直在变,所以评测系统必须能快速重新对齐
有了文档即 Agent 和 Agent Tree,还不等于评测系统就可靠了。
真正落地时,客户给到的原始材料通常不是一段可以直接运行的 Prompt,而是一套面向人工标注的质量规范。它里面会描述什么是好回答、什么是坏回答、哪些情况要扣分、哪些场景要重点关注。
要把它变成可用评测 Agent,我实际走的是这个 loop:
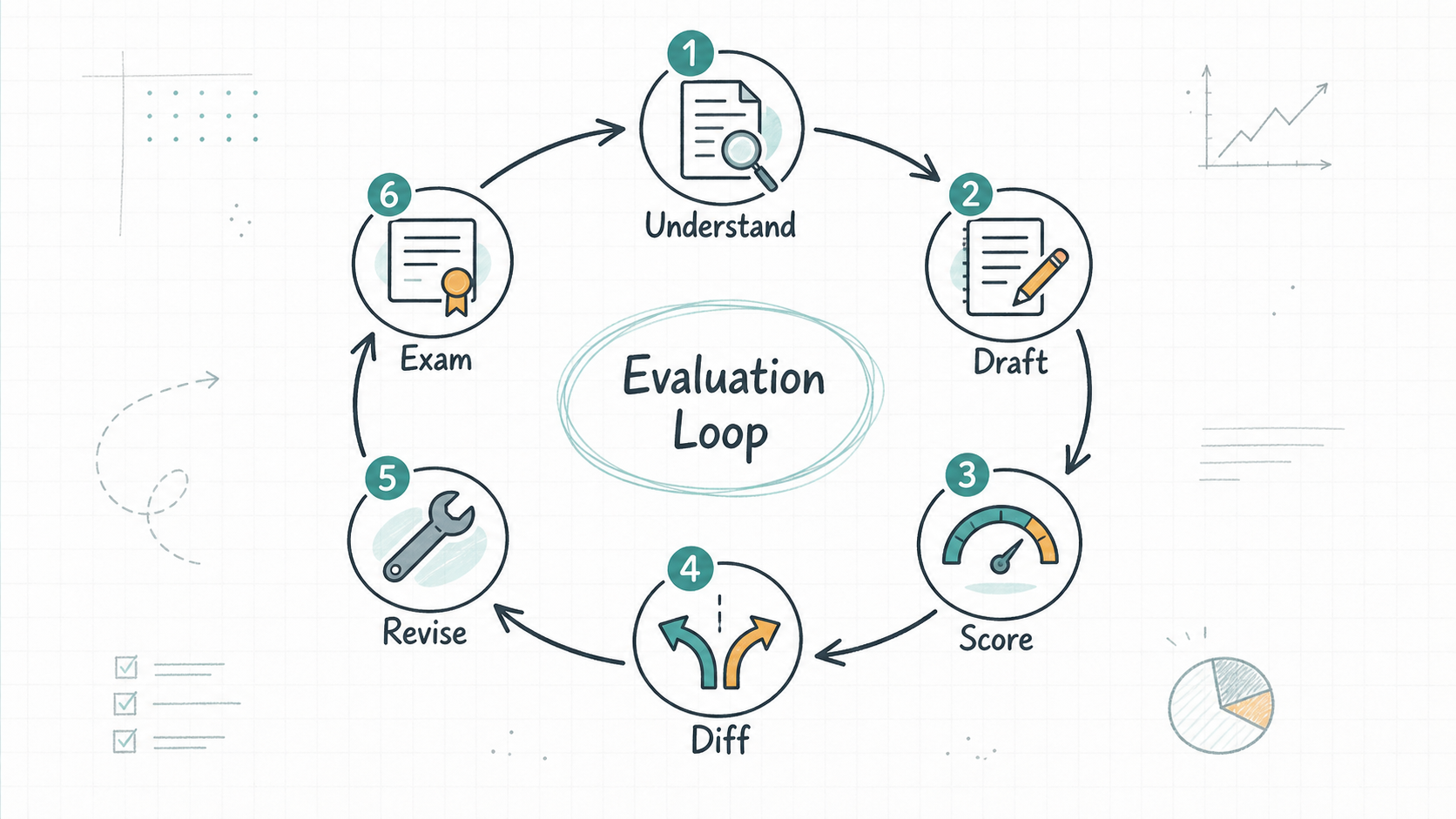
第一步,理解客户标准。
把客户标注规范、验收逻辑、历史 badcase 拆成评分维度、红线规则、意图分类、输出字段。这里最重要的不是“把文档抄进 Prompt”,而是理解标准背后的产品意图。
第二步,生成 Agent 文档初版。
把评分维度、流程节点、工具使用方式、输出字段整理成 Markdown Agent 文档。这个过程不只是写 Prompt,而是在设计一套可执行流程:什么问题先被拦截,哪些事实必须通过工具核查,哪些意图应该走不同 rubric,最终结果如何结构化提交。
第三步,跑分验证。
用 Agent 对样本集跑分,观察分数分布、reasoning 和错分样本。这里不能只看平均分,而要看它是否能抓到真实 badcase:事实错的有没有低分,答非所问的有没有低分,引用不可靠的有没有低分,边界风险有没有被拦截。
第四步,看分歧。
把机评结果和人工标注、专家审核标尺对齐,找出分歧最大的 case。分歧不一定说明 Agent 错,也可能说明原始规则不够清晰,或者人工标注存在知识盲区。
第五步,修改文档,再考试。
根据分歧修改 Agent 文档,必要时调整工具使用方式和子 Agent 拆分,再重新跑分,直到考试结果达到可接受水位。
这套 loop 跑通以后,新客户或新垂直场景的支持周期就被明显压缩了。不是每次从零开发一套评分器,而是在已有平台能力上,快速构建一份贴合客户标准的评测文档,并通过考试机制验证它是否真的可用。
七、别相信“看起来合理”,让评分 Agent 也参加考试
评测系统最危险的地方在于:它很容易“看起来很合理”。
Agent 能输出评分,能输出 reasoning,能生成 JSON,甚至能写出一段非常像专家的分析。但这不代表它真的对齐了客户标准。
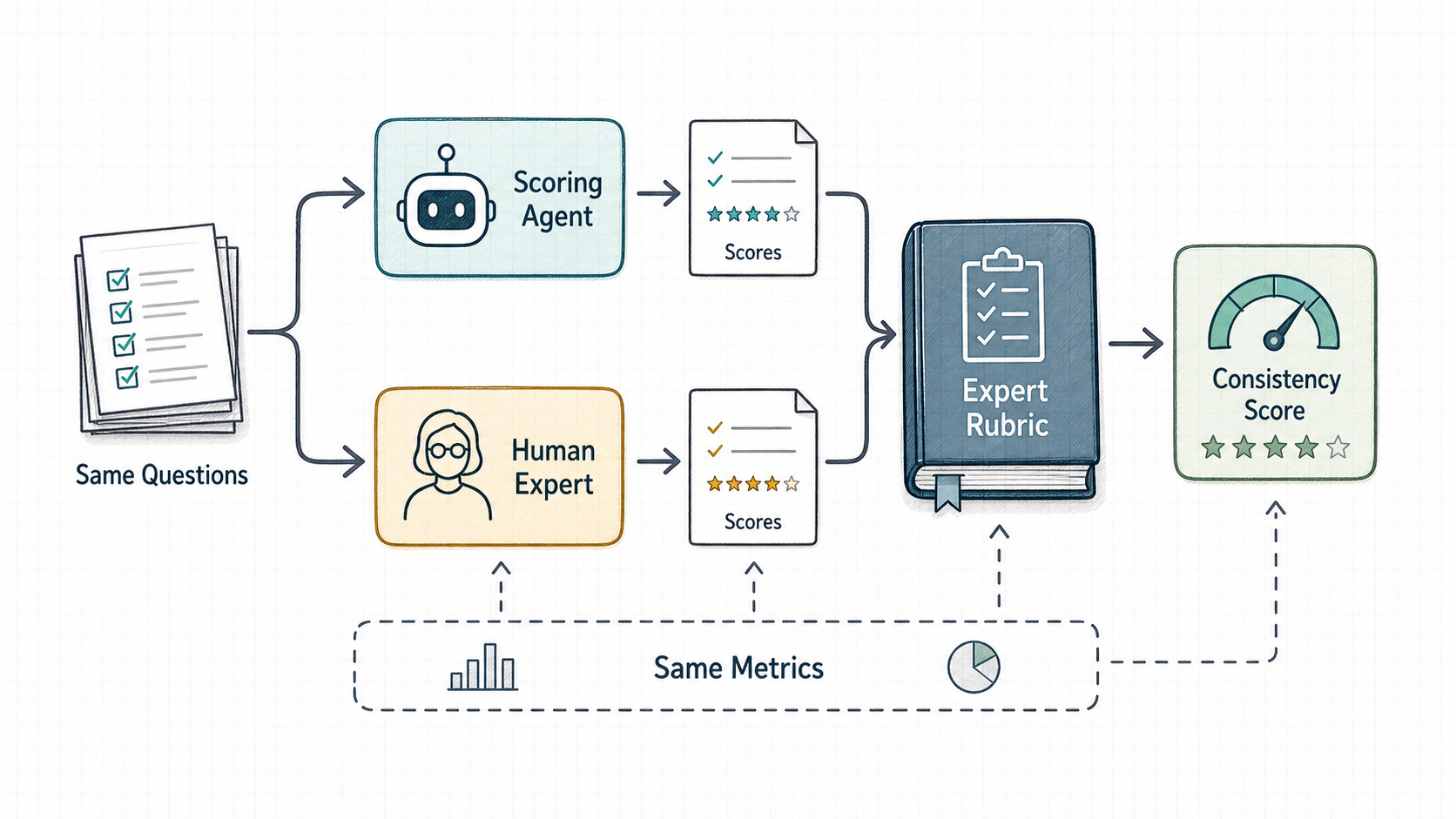
所以我做了一个关键机制:标注考试。
思路很简单:人工标注员要通过考试才能上岗,评分 Agent 也应该通过考试才能进入主评测链路。
考试系统里有三件事。
第一,同一套题集。
Agent 和人工评分使用同一批题,而不是各自做不同样本。否则结果没有可比性。
第二,同一套标尺。
这里的标尺不是某一个人的单次打分,而是多组打分后,再由专家小组审核制定的标准答案。也就是说,它衡量的不是“两个专家之间是否互相一致”,而是某个评分者和专家审核标尺是否一致。
第三,同一套一致性指标。
我使用一致性指标来衡量评分者和标尺的对齐程度。比如线性加权 Kappa 可以衡量离散分数上的一致性,并考虑随机一致的可能性;ICC 可以作为补充,观察评分者之间的绝对一致性和系统性偏差。
在这套机制下,前面提到的结果才有意义:
| 对象 | 与专家审核标尺的一致性分数 |
|---|---|
| 评分 Agent | 80.1 |
| 人工专家评分 | 52.8 |
这个结果需要准确理解。
它不是说以后不需要人工标注。恰恰相反,专家标尺、分歧复盘、规则修订仍然离不开人。
它说明的是:结构化协议 + 工具化事实核查 + 稳定执行,让 Agent 在“按同一套标准判分”这件事上具备了更强一致性。
Agent 也会犯错,但它有一个优势:只要评测协议写清楚、工具链设计好、考试持续校准,它可以更稳定地执行同一套标准。
八、工程上最重要的几件事
前面讲的是设计和证明。真正做成平台,还需要几个不太显眼但很关键的工程点。
1. 上下文不能让子 Agent 自己找
Agent Tree 里会有很多子 Agent,比如事实核查、意图判断、rubric 打分、多模态分析等。
如果每个子 Agent 都自己通过工具获取 query、response、search results,会带来两个问题:成本和耗时上升,Prompt 也更复杂,容易漏掉上下文。
所以更合理的做法是把评测上下文通过运行时机制统一注入。子 Agent 只需要专注完成自己的判断任务,不需要关心上下文从哪里来。
这个设计看起来不显眼,但它决定了系统能不能规模化运行。
2. 结构化输出不能靠模型自觉
很多 Agent demo 会让模型“最后输出一个 JSON”。这在小样本里能工作,但在生产评测里不够稳。
我的做法是让顶层 Agent 必须通过专门的提交动作提交结果。这个提交动作定义了允许写入的字段、字段类型和结果白名单。这样即使不同客户有不同输出字段,最终也能进入统一的数据表、报表和 badcase 分析链路。
简单说,就是不要把结构化结果寄托在模型最后一段文本上,而要让结果提交成为可约束的系统动作。
3. 可观测性必须从第一天做
多 Agent 系统最怕的问题是:分数错了,但不知道谁错了。
所以每一次评分都应该记录关键事件:顶层 Agent 如何规划,哪些子 Agent 被调用,子 Agent 的输入和输出是什么,调用了哪些工具,最终提交了哪些字段,哪个节点导致了低分或异常。
对 AI Native 系统来说,可观测性不是锦上添花。Agent 不是传统确定性代码,它的行为会受模型、Prompt、上下文、工具结果影响。如果没有可观测性,后面所有调优都会变成玄学。
4. 失败样本也要能留下来
真实评测任务里,Agent 不是每次都完美执行。有时模型没有完成最终提交,有时某个字段缺失,有时工具调用失败,有时中间节点输出异常。
评测平台一旦承载大量任务,最怕的不是单条失败,而是失败后没有可追溯结果。
所以结果提取要有兜底:正常提交时读取结构化字段,异常时尽量保留中间结果和错误原因,把样本标记为不完整,而不是直接丢掉。失败样本本身也是重要资产,它会告诉你评测协议哪里不稳。
九、落地之后,评测变成了数据飞轮
当评测系统跑起来以后,它的价值不只是省掉一部分人工打分成本。
更重要的是,它开始改变模型迭代方式。
以前评测更像一个阶段性验收动作:跑一批样本,看平均分,挑几个 badcase,开会讨论。
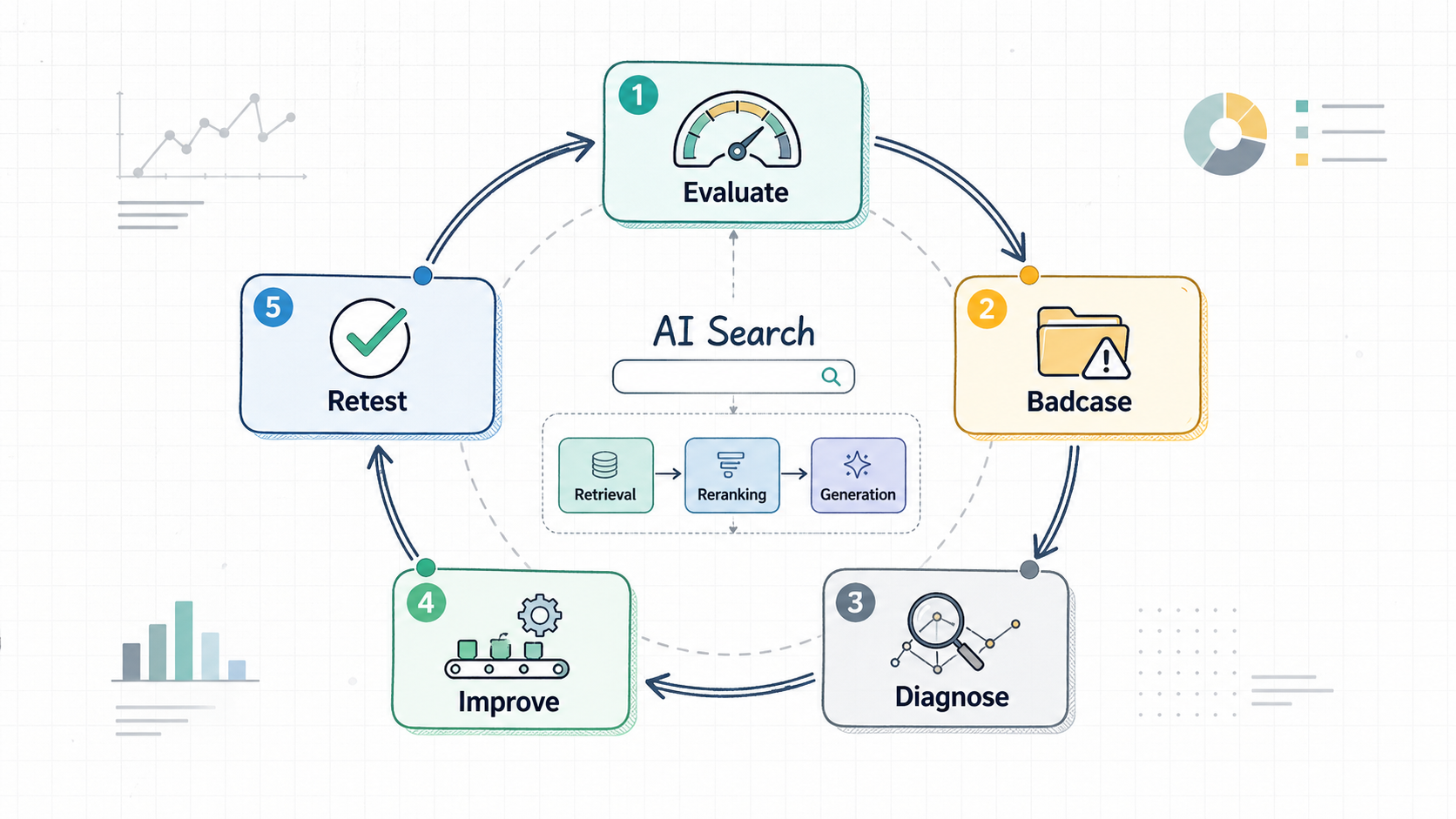
后来评测变成一条持续运行的链路:
- 新版本上线前,自动跑评测;
- 低分样本进入 badcase 池;
- badcase 按事实错误、意图误判、格式问题、检索缺陷、风险边界分类;
- 不同类型问题回流到不同模块;
- 修复后再跑同一套考试和评测集,观察分布是否真的改善。
在这个过程中,评测系统不再只是一个“裁判”,而是 AI 搜索迭代的基础设施。
后来这套系统也承载了数千个评测任务、数十万条评测结果,并沉淀了一批可以反哺模型和链路迭代的 badcase。这里不展开具体业务数字,公开博客里更想强调的是方法本身:
当评测标准可以被文档化、执行、校准和复用以后,评测就从一次性项目变成了平台能力。
十、方法论总结:AI Native 评测的三条原则
这套系统做下来,我觉得最核心的不是某个模型、某段 Prompt、某个工具,而是三条原则。
1. 评测标准的载体决定迭代速度
如果标准在代码里,每一次客户变化都会变成开发任务。
如果标准在文档里,并且文档可以被系统执行,那么客户标准就变成了可维护资产。
这就是“文档即 Agent”的价值。它不是为了形式上好看,而是为了让业务规则能被快速修改、审计、复用和校准。
2. 专职 Agent + 工具链,比单 Prompt 更可靠
一个通用 Judge 很难同时做好红线审查、事实核查、意图判断、rubric 打分和规则扣分。
拆成专职 Agent 后,每个节点只解决一个更明确的问题。事实核查就专注查事实,rubric 就专注按标准评分,Penalty 就专注处理规则扣分。
这不是为了堆 Agent 概念,而是为了减少单点 Prompt 的模糊性,让每个判断都更容易观察、调试和迭代。
3. 不要靠感觉判断 Agent 是否可用
Agent 能输出理由,不代表它真的对。
评测 Agent 必须被评测。最直接的方法就是考试:同一套题集、同一套标尺、同一套指标,把不同版本的 Agent、不同评分协议、不同模型配置放在一起比较。
跑不过考试的 Agent,就是还不能进入主评测链路。
十一、还有哪些事情没做完
这套系统跑通以后,我反而更清楚后面还有哪些事情值得继续做。
第一,自动化客户文档到 Agent 文档的过程。
现在客户提供的是评分标准和业务逻辑,我们负责把它进一步构建成可执行的评测文档。这一步已经可以让 Agent 辅助,但还没有完全自动化。未来可以把“规范理解、rubric 生成、边界 case 补充、输出字段设计”做成更系统的流程。
第二,自动化 Agent 自我迭代的过程。
现在的迭代主要是跑分、看分歧、人工分析、修改文档。下一步可以让系统根据分歧 case 自动生成修改建议,指出是哪条 rubric 不清楚、哪个工具调用不充分、哪个子 Agent 的判断不稳定,再由人审核后更新。
第三,引入 SBS 对比评测。
当前完成的是绝对打分评测。如果要做新旧版本、竞品或 A/B 对比,Side-by-Side 通常会更准,因为它直接比较两个回答在同一问题下谁更好。
第四,构建更强的平台分析能力。
未来评测平台不应该只给分,还应该支持消融实验、自动报告、自动分析和仪表盘。比如同一批样本上,去掉事实核查 Agent 会怎样,换一套 rubric 会怎样,某个模型版本在哪类 query 上退化最明显,这些都应该自动产出。
第五,持续构建更好的评测数据集。
评测 Agent 的上限,很大程度上取决于评测数据集的上限。
前期为了快速对齐客户判断,数据集往往来自客户筛选出来的 badcase 或者高难 case。这类样本很有价值,因为它能逼出搜索 Agent 的问题,也能帮助评测 Agent 快速学会客户最在意的扣分边界。
但它也会带来一个副作用:如果数据集长期过于集中在难例和坏例上,评测 Agent 为了对齐人的判断,可能会变得过分严格。到了其他类型的数据集上,它就可能出现过严误判,或者在某些边界上偶尔误判、偶尔漏判。
所以数据集构建不是一次性工作,而是一个无穷尽的迭代过程。后续需要持续补充不同难度、不同意图、不同业务场景、不同质量水位的样本,让评测 Agent 不只会抓坏例,也能稳定区分普通样本、边界样本和高质量样本。
更理想的形态是:评测系统根据分歧、错判、漏判和新出现的 badcase,自动生成数据集补充建议;再根据更新后的数据集,自动迭代出更好的评测 Agent。数据集、评测 Agent 和实际搜索 Agent 会形成一个更大的闭环,三者共同决定最终效果上限。
结语
回头看,我做这套评测系统时,最大的认知变化是:
评测不是让大模型随便打个分,而是把客户标准变成可执行、可校准、可复用、可证明可靠的评分协议。
LLM as Judge 是一个很好的起点,但裸用 Judge 解决不了 ToB AI 搜索的核心问题。真正有用的是把客户标准文档化,把文档编译成 Agent Tree,把评分结果放进考试和数据飞轮里,再用分歧和 badcase 持续校准它。
当这条链路跑通以后,评测就不再是模型迭代最后的验收动作,而会变成 AI 搜索交付和持续优化的基础设施。
References
- Papineni et al., 2002. BLEU: a Method for Automatic Evaluation of Machine Translation.
- Lin, 2004. ROUGE: A Package for Automatic Evaluation of Summaries.
- Liu et al., 2023. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment.
- Wang et al., 2023. Large Language Models are not Fair Evaluators.
- Zheng et al., 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.
- Kim et al., 2023. Prometheus: Inducing Fine-grained Evaluation Capability in Language Models.
- Dubois et al., 2024. Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators.
- Li et al., 2024. LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods.
评论
留言会在审核后显示。